иѓЊз®ЛзЃАдїЛпЉЪ
иБЪзД¶PythonеИЖеЄГеЉПзИђиЩЂењЕе≠¶ж°ЖжЮґScrapy жЙУйА†жРЬ糥еЉХжУО
жЬ™жЭ•жШѓдїАдєИжЧґдї£пЉЯжШѓжХ∞жНЃжЧґдї£пЉБжХ∞жНЃеИЖжЮРжЬНеК°гАБдЇТиБФзљСйЗСиЮНпЉМжХ∞жНЃеїЇж®°гАБиЗ™зДґиѓ≠и®Ае§ДзРЖгАБеМїзЦЧзЧЕдЊЛеИЖжЮРвА¶вА¶иґКжЭ•иґКе§ЪзЪДеЈ•дљЬдЉЪеЯЇдЇОжХ∞жНЃжЭ•еБЪпЉМиАМзИђиЩЂж≠£жШѓењЂйАЯиОЈеПЦжХ∞жНЃжЬАйЗНи¶БзЪДжЦєеЉПпЉМзЫЄжѓФеЕґеЃГиѓ≠и®АпЉМPythonзИђиЩЂжЫізЃАеНХгАБйЂШжХИ
дїО0иЃ≤иІ£зИђиЩЂеЯЇжЬђеОЯзРЖпЉМеѓєзИђиЩЂдЄ≠жЙАйЬАи¶БзФ®еИ∞зЪДзЯ•иѓЖзВєињЫи°МжҐ≥зРЖпЉМдїОжР≠еїЇеЉАеПСзОѓеҐГгАБиЃЊиЃ°жХ∞жНЃеЇУеЉАеІЛпЉМйАЪињЗзИђеПЦдЄЙдЄ™зЯ•еРНзљСзЂЩзЪДзЬЯеЃЮжХ∞жНЃпЉМеЄ¶дљ†зФ±жµЕеЕ•жЈ±зЪДжОМжП°ScrapyеОЯзРЖгАБеРДж®°еЭЧдљњзФ®гАБзїДдїґеЉАеПСпЉМScrapyзЪДињЫйШґеЉАеПСдї•еПКеПНзИђиЩЂзЪДз≠ЦзХ•
ељїеЇХжОМжП°ScrapyдєЛеРОпЉМеЄ¶дљ†еЯЇдЇОScrapyгАБRedisгАБelasticsearchеТМdjangoжЙУйА†дЄАдЄ™еЃМжХізЪДжРЬ糥еЉХжУОзљСзЂЩ
иѓЊз®ЛжЭ•жЇРйУЊжО•пЉЪhttp://coding.imooc.com/class/92.html
иѓЊз®ЛзЫЃељХпЉЪ
зђђ1зЂ† иѓЊз®ЛдїЛзїН
дїЛзїНиѓЊз®ЛзЫЃж†ЗгАБйАЪињЗиѓЊз®ЛиГље≠¶дє†еИ∞зЪДеЖЕеЃєгАБеТМз≥їзїЯеЉАеПСеЙНйЬАи¶БеЕЈе§ЗзЪДзЯ•иѓЖ
1-1 pythonеИЖеЄГеЉПзИђиЩЂжЙУйА†жРЬ糥еЉХжУОзЃАдїЛ
зђђ2зЂ† windowsдЄЛжР≠еїЇеЉАеПСзОѓеҐГ
дїЛзїНй°єзЫЃеЉАеПСйЬАи¶БеЃЙи£ЕзЪДеЉАеПСиљѓдїґгАБ pythonиЩЪжЛЯvirtualenvеТМ virtualenvwrapperзЪДеЃЙи£ЕеТМдљњзФ®гАБ жЬАеРОдїЛзїНpycharmеТМnavicatзЪДзЃАеНХдљњзФ®
2-1 pycharmзЪДеЃЙи£ЕеТМзЃАеНХдљњзФ®
2-2 mysqlеТМnavicatзЪДеЃЙи£ЕеТМдљњзФ®
2-3 windowsеТМlinuxдЄЛеЃЙи£Еpython2еТМpython3
2-4 иЩЪжЛЯзОѓеҐГзЪДеЃЙи£ЕеТМйЕНзљЃ
зђђ3зЂ† зИђиЩЂеЯЇз°АзЯ•иѓЖеЫЮй°Њ
дїЛзїНзИђиЩЂеЉАеПСдЄ≠йЬАи¶БзФ®еИ∞зЪДеЯЇз°АзЯ•иѓЖеМЕжЛђзИђиЩЂиГљеБЪдїАдєИпЉМж≠£еИЩи°®иЊЊеЉПпЉМжЈ±еЇ¶дЉШеЕИеТМеєњеЇ¶дЉШеЕИзЪДзЃЧж≥ХеПКеЃЮзО∞гАБзИђиЩЂurlеОїйЗНзЪДз≠ЦзХ•гАБељїеЇХеЉДжЄЕж•ЪunicodeеТМutf8mb4зЉЦз†БзЪДеМЇеИЂеТМеЇФзФ®гАВ
3-1 жКАжЬѓйАЙеЮЛ зИђиЩЂиГљеБЪдїАдєИ
3-2 ж≠£еИЩи°®иЊЊеЉП-1
3-3 ж≠£еИЩи°®иЊЊеЉП-2
3-4 ж≠£еИЩи°®иЊЊеЉП-3
3-5 жЈ±еЇ¶дЉШеЕИеТМеєњеЇ¶дЉШеЕИеОЯзРЖ
3-6 urlеОїйЗНжЦєж≥Х
3-7 ељїеЇХжРЮжЄЕж•ЪunicodeеТМutf8mb4зЉЦз†Б
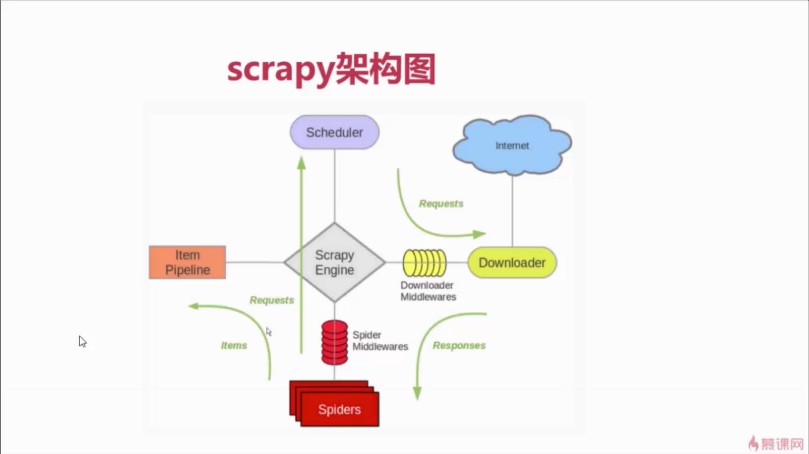
зђђ4зЂ† scrapyзИђеПЦзЯ•еРНжКАжЬѓжЦЗзЂ†зљСзЂЩ
жР≠еїЇscrapyзЪДеЉАеПСзОѓеҐГпЉМжЬђзЂ†дїЛзїНscrapyзЪДеЄЄзФ®еСљдї§дї•еПКеЈ•з®ЛзЫЃељХзїУжЮДеИЖжЮРпЉМжЬђзЂ†дЄ≠дєЯдЉЪиѓ¶зїЖзЪДиЃ≤иІ£xpathеТМcssйАЙжЛ©еЩ®зЪДдљњзФ®гАВзДґеРОйАЪињЗscrapyжПРдЊЫзЪДspiderеЃМжИРжЙАжЬЙжЦЗзЂ†зЪДзИђеПЦгАВзДґеРОиѓ¶зїЖиЃ≤иІ£itemдї•еПКitem loaderжЦєеЉПеЃМжИРеЕЈдљУе≠ЧжЃµзЪДжПРеПЦеРОдљњзФ®scrapyжПРдЊЫзЪДpipelineеИЖеИЂе∞ЖжХ∞жНЃдњЭе≠ШеИ∞jsonжЦЗдїґдї•еПКmysqlжХ∞жНЃеЇУдЄ≠гАВ...
4-1 scrapyеЃЙи£Едї•еПКзЫЃељХзїУжЮДдїЛзїН
4-2 pycharm и∞ГиѓХscrapy жЙІи°МжµБз®Л
4-3 xpathзЪДзФ®ж≥Х - 1
4-4 xpathзЪДзФ®ж≥Х - 2
4-5 xpathзЪДзФ®ж≥Х - 3
4-6 cssйАЙжЛ©еЩ®еЃЮзО∞е≠ЧжЃµиІ£жЮР - 1
4-7 cssйАЙжЛ©еЩ®еЃЮзО∞е≠ЧжЃµиІ£жЮР - 2
4-8 зЉЦеЖЩspiderзИђеПЦjobboleзЪДжЙАжЬЙжЦЗзЂ† - 1
4-9 зЉЦеЖЩspiderзИђеПЦjobboleзЪДжЙАжЬЙжЦЗзЂ† - 2
4-10 itemsиЃЊиЃ° - 1
4-11 itemsиЃЊиЃ° - 2
4-12 itemsиЃЊиЃ° - 3
4-13 жХ∞жНЃи°®иЃЊиЃ°еТМдњЭе≠ШitemеИ∞jsonжЦЗдїґ
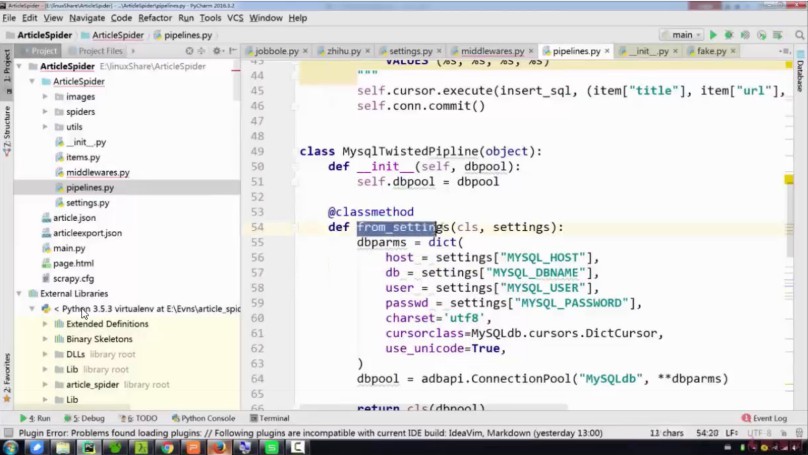
4-14 йАЪињЗpipelineдњЭе≠ШжХ∞жНЃеИ∞mysql - 1
4-15 йАЪињЗpipelineдњЭе≠ШжХ∞жНЃеИ∞mysql - 2
4-16 scrapy item loaderжЬЇеИґ - 1
4-17 scrapy item loaderжЬЇеИґ- 2
зђђ5зЂ† scrapyзИђеПЦзЯ•еРНйЧЃз≠ФзљСзЂЩ
жЬђзЂ†дЄїи¶БеЃМжИРзљСзЂЩзЪДйЧЃйҐШеТМеЫЮз≠ФзЪДжПРеПЦгАВжЬђзЂ†йЩ§дЇЖеИЖжЮРеЗЇйЧЃз≠ФзљСзЂЩзЪДзљСзїЬиѓЈж±Вдї•е§ЦињШдЉЪеИЖеИЂйАЪињЗrequestsеТМscrapyзЪДFormRequestдЄ§зІНжЦєеЉПеЃМжИРзљСзЂЩзЪДж®°жЛЯзЩїељХпЉМ жЬђзЂ†иѓ¶зїЖзЪДеИЖжЮРдЇЖзљСзЂЩзЪДзљСзїЬиѓЈж±ВеєґеИЖеИЂеИЖжЮРеЗЇдЇЖзљСзЂЩйЧЃйҐШеЫЮз≠ФзЪДapiиѓЈж±ВжО•еП£еєґе∞ЖжХ∞жНЃжПРеПЦеЗЇжЭ•еРОдњЭе≠ШеИ∞mysqlдЄ≠гАВ...
5-1 sessionеТМcookieиЗ™еК®зЩїељХжЬЇеИґ
5-2 пЉИи°•еЕЕпЉЙseleniumж®°жЛЯзЯ•дєОзЩїељХ-2017-12-29
5-3 requestsж®°жЛЯзЩїйЩЖзЯ•дєО - 1
5-4 requestsж®°жЛЯзЩїйЩЖзЯ•дєО - 2
5-5 requestsж®°жЛЯзЩїйЩЖзЯ•дєО - 3
5-6 scrapyж®°жЛЯзЯ•дєОзЩїељХ
5-7 зЯ•дєОеИЖжЮРдї•еПКжХ∞жНЃи°®иЃЊиЃ°1
5-8 зЯ•дєОеИЖжЮРдї•еПКжХ∞жНЃи°®иЃЊиЃ° - 2
5-9 item loderжЦєеЉПжПРеПЦquestion - 1
5-10 item loderжЦєеЉПжПРеПЦquestion - 2
5-11 item loderжЦєеЉПжПРеПЦquestion - 3
5-12 зЯ•дєОspiderзИђиЩЂйАїиЊСзЪДеЃЮзО∞дї•еПКanswerзЪДжПРеПЦ - 1
5-13 зЯ•дєОspiderзИђиЩЂйАїиЊСзЪДеЃЮзО∞дї•еПКanswerзЪДжПРеПЦ - 2
5-14 дњЭе≠ШжХ∞жНЃеИ∞mysqlдЄ≠ -1
5-15 дњЭе≠ШжХ∞жНЃеИ∞mysqlдЄ≠ -2
5-16 дњЭе≠ШжХ∞жНЃеИ∞mysqlдЄ≠ -3
5-17 (и°•еЕЕе∞ПиКВ)зЯ•дєОй™МиѓБз†БзЩїељХ - 1_1
5-18 (и°•еЕЕе∞ПиКВ)зЯ•дєОй™МиѓБз†БзЩїељХ - 2_1
5-19 пЉИи°•еЕЕпЉЙзЯ•дєОеАТзЂЛжЦЗе≠ЧиѓЖеИЂ-1
5-20 пЉИи°•еЕЕпЉЙзЯ•дєОеАТзЂЛжЦЗе≠ЧиѓЖеИЂ-2
зђђ6зЂ† йАЪињЗCrawlSpiderеѓєжЛЫиБШзљСзЂЩињЫи°МжХізЂЩзИђеПЦ
жЬђзЂ†еЃМжИРжЛЫиБШзљСзЂЩиБМдљНзЪДжХ∞жНЃи°®зїУжЮДиЃЊиЃ°пЉМеєґйАЪињЗlink extractorеТМruleзЪД嚥еЉПеєґйЕНзљЃCrawlSpiderеЃМжИРжЛЫиБШзљСзЂЩжЙАжЬЙиБМдљНзЪДзИђеПЦпЉМжЬђзЂ†дєЯдЉЪдїОжЇРз†БзЪДиІТеЇ¶жЭ•еИЖжЮРCrawlSpiderиЃ©е§ІеЃґеѓєCrawlSpiderжЬЙжЈ±еЕ•зЪДзРЖиІ£гАВ
6-1 жХ∞жНЃи°®зїУжЮДиЃЊиЃ°
6-2 CrawlSpiderжЇРз†БеИЖжЮР-жЦ∞еїЇCrawlSpiderдЄОsettingsйЕНзљЃ
6-3 CrawlSpiderжЇРз†БеИЖжЮР
6-4 RuleеТМLinkExtractorдљњзФ®
6-5 item loaderжЦєеЉПиІ£жЮРиБМдљН
6-6 иБМдљНжХ∞жНЃеЕ•еЇУ-1
6-7 иБМдљНдњ°жБѓеЕ•еЇУ-2
зђђ7зЂ† Scrapyз™Бз†іеПНзИђиЩЂзЪДйЩРеИґ
жЬђзЂ†дЉЪдїОзИђиЩЂеТМеПНзИђиЩЂзЪДжЦЧдЇЙињЗз®ЛеЉАеІЛиЃ≤иІ£пЉМзДґеРОиЃ≤иІ£scrapyзЪДеОЯзРЖпЉМзДґеРОйАЪињЗйЪПжЬЇеИЗжНҐuser-agentеТМиЃЊзљЃscrapyзЪДipдї£зРЖзЪДжЦєеЉПеЃМжИРз™Бз†іеПНзИђиЩЂзЪДеРДзІНйЩРеИґгАВжЬђзЂ†дєЯдЉЪиѓ¶зїЖдїЛзїНhttpresponseеТМhttprequestжЭ•иѓ¶зїЖзЪДеИЖжЮРscrapyзЪДеКЯиГљпЉМжЬАеРОдЉЪйАЪињЗдЇСжЙУз†Беє≥еП∞жЭ•еЃМжИРеЬ®зЇњй™МиѓБз†БиѓЖеИЂдї•еПКз¶БзФ®cookieеТМиЃњйЧЃйҐСзОЗжЭ•йЩНдљОзИђиـ襀е±ПиФљзЪДеПѓиГљжАІгАВ...
7-1 зИђиЩЂеТМеПНзИђзЪДеѓєжКЧињЗз®Лдї•еПКз≠ЦзХ•
7-2 scrapyжЮґжЮДжЇРз†БеИЖжЮР
7-3 RequestsеТМResponseдїЛзїН
7-4 йАЪињЗdownloadmiddlewareйЪПжЬЇжЫіжНҐuser-agent-1
7-5 йАЪињЗdownloadmiddlewareйЪПжЬЇжЫіжНҐuser-agent - 2
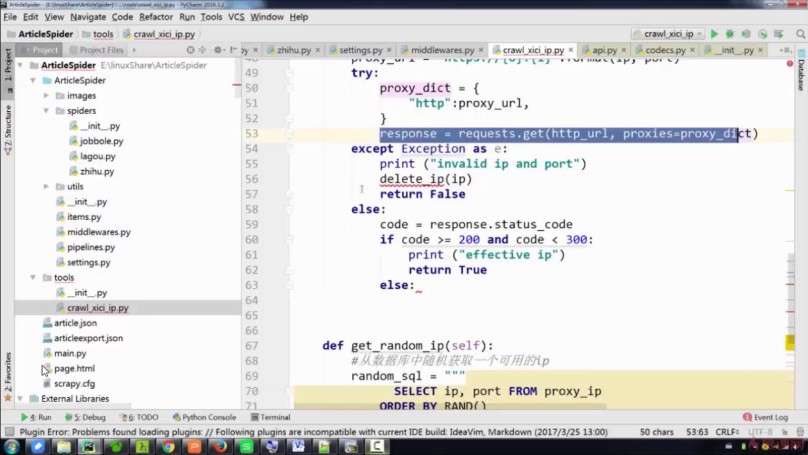
7-6 scrapyеЃЮзО∞ipдї£зРЖ汆 - 1
7-7 scrapyеЃЮзО∞ipдї£зРЖ汆 - 2
7-8 scrapyеЃЮзО∞ipдї£зРЖ汆 - 3
7-9 дЇСжЙУз†БеЃЮзО∞й™МиѓБз†БиѓЖеИЂ
7-10 cookieз¶БзФ®гАБиЗ™еК®йЩРйАЯгАБиЗ™еЃЪдєЙspiderзЪДsettings
зђђ8зЂ† scrapyињЫйШґеЉАеПС
жЬђзЂ†е∞ЖиЃ≤иІ£scrapyзЪДжЫіе§ЪйЂШзЇІзЙєжАІпЉМињЩдЇЫйЂШзЇІзЙєжАІеМЕжЛђйАЪињЗseleniumеТМphantomjsеЃЮзО∞еК®жАБзљСзЂЩжХ∞жНЃзЪДзИђеПЦдї•еПКе∞ЖињЩдЇМиАЕйЫЖжИРеИ∞scrapyдЄ≠гАБscrapyдњ°еПЈгАБиЗ™еЃЪдєЙдЄ≠йЧідїґгАБжЪВеБЬеТМеРѓеК®scrapyзИђиЩЂгАБscrapyзЪДж†ЄењГapiгАБscrapyзЪДtelnetгАБscrapyзЪДweb serviceеТМscrapyзЪДlogйЕНзљЃеТМemailеПСйАБз≠ЙгАВ ињЩдЇЫзЙєжАІдљњеЊЧжИСдїђдЄНдїЕеП™жШѓеПѓдї•йАЪињЗscrapyжЭ•еЃМжИР...
8-1 seleniumеК®жАБзљСй°µиѓЈж±ВдЄОж®°жЛЯзЩїељХзЯ•дєО
8-2 seleniumж®°жЛЯзЩїељХеЊЃеНЪпЉМ ж®°жЛЯйЉ†ж†ЗдЄЛжЛЙ
8-3 chromedriverдЄНеК†иљљеЫЊзЙЗгАБphantomjsиОЈеПЦеК®жАБзљСй°µ
8-4 seleniumйЫЖжИРеИ∞scrapyдЄ≠
8-5 еЕґдљЩеК®жАБзљСй°µиОЈеПЦжКАжЬѓдїЛзїН-chromeжЧ†зХМйЭҐињРи°МгАБscrapy-splashгАБselenium-grid, splinter
8-6 scrapyзЪДжЪВеБЬдЄОйЗНеРѓ
8-7 scrapy urlеОїйЗНеОЯзРЖ
8-8 scrapy telnetжЬНеК°
8-9 spider middleware иѓ¶иІ£
8-10 scrapyзЪДжХ∞жНЃжФґйЫЖ
8-11 scrapyдњ°еПЈиѓ¶иІ£
8-12 scrapyжЙ©е±ХеЉАеПС
зђђ9зЂ† scrapy-redisеИЖеЄГеЉПзИђиЩЂ
Scrapy-redisеИЖеЄГеЉПзИђиЩЂзЪДдљњзФ®дї•еПКscrapy-redisзЪДеИЖеЄГеЉПзИђиЩЂзЪДжЇРз†БеИЖжЮРпЉМ иЃ©е§ІеЃґеПѓдї•ж†єжНЃиЗ™еЈ±зЪДйЬАж±ВжЭ•дњЃжФєжЇРз†Бдї•жї°иґ≥иЗ™еЈ±зЪДйЬАж±ВгАВжЬАеРОдєЯдЉЪиЃ≤иІ£е¶ВдљХе∞ЖbloomfilterйЫЖжИРеИ∞scrapy-redisдЄ≠гАВ
9-1 еИЖеЄГеЉПзИђиЩЂи¶БзВє
9-2 redisеЯЇз°АзЯ•иѓЖ - 1
9-3 redisеЯЇз°АзЯ•иѓЖ - 2
9-4 scrapy-redisзЉЦеЖЩеИЖеЄГеЉПзИђиЩЂдї£з†Б
9-5 scrapyжЇРз†БиІ£жЮР-connection.pyгАБdefaults.py-
9-6 scrapy-redisжЇРз†БеЙЦжЮР-dupefilter.py-
9-7 scrapy-redisжЇРз†БеЙЦжЮР- pipelines.pyгАБ queue.py-
9-8 scrapy-redisжЇРз†БеИЖжЮР- scheduler.pyгАБspider.py-
9-9 йЫЖжИРbloomfilterеИ∞scrapy-redisдЄ≠
зђђ10зЂ† elasticsearchжРЬ糥еЉХжУОзЪДдљњзФ®
жЬђзЂ†е∞ЖиЃ≤иІ£elasticsearchзЪДеЃЙи£ЕеТМдљњзФ®пЉМе∞ЖиЃ≤иІ£elasticsearchзЪДеЯЇжЬђж¶ВењµзЪДдїЛзїНдї•еПКapiзЪДдљњзФ®гАВжЬђзЂ†дєЯдЉЪиЃ≤иІ£жРЬ糥еЉХжУОзЪДеОЯзРЖеєґиЃ≤иІ£elasticsearch-dslзЪДдљњзФ®пЉМжЬАеРОиЃ≤иІ£е¶ВдљХйАЪињЗscrapyзЪДpipelineе∞ЖжХ∞жНЃдњЭе≠ШеИ∞elasticsearchдЄ≠гАВ
10-1 elasticsearchдїЛзїН
10-2 elasticsearchеЃЙи£Е
10-3 elasticsearch-headжПТдїґдї•еПКkibanaзЪДеЃЙи£Е
10-4 elasticsearchзЪДеЯЇжЬђж¶Вењµ
10-5 еАТжОТ糥еЉХ
10-6 elasticsearch еЯЇжЬђзЪД糥еЉХеТМжЦЗж°£CRUDжУНдљЬ
10-7 elasticsearchзЪДmgetеТМbulkжЙєйЗПжУНдљЬ
10-8 elasticsearchзЪДmappingжШ†е∞ДзЃ°зРЖ
10-9 elasticsearchзЪДзЃАеНХжߕ胥 - 1
10-10 elasticsearchзЪДзЃАеНХжߕ胥 - 2
10-11 elasticsearchзЪДboolзїДеРИжߕ胥
10-12 scrapyеЖЩеЕ•жХ∞жНЃеИ∞elasticsearchдЄ≠ - 1
10-13 scrapyеЖЩеЕ•жХ∞жНЃеИ∞elasticsearchдЄ≠ - 2
зђђ11зЂ† djangoжР≠еїЇжРЬ糥зљСзЂЩ
жЬђзЂ†иЃ≤иІ£е¶ВдљХйАЪињЗdjangoењЂйАЯжР≠еїЇжРЬ糥зљСзЂЩпЉМ жЬђзЂ†дєЯдЉЪиЃ≤иІ£е¶ВдљХеЃМжИРdjangoдЄОelasticsearchзЪДжРЬ糥жߕ胥䯧дЇТгАВ
11-1 esеЃМжИРжРЬ糥忯聁-жРЬ糥忯聁е≠ЧжЃµдњЭе≠Ш - 1
11-2 esеЃМжИРжРЬ糥忯聁-жРЬ糥忯聁е≠ЧжЃµдњЭе≠Ш - 2
11-3 djangoеЃЮзО∞elasticsearchзЪДжРЬ糥忯聁 - 1
11-4 djangoеЃЮзО∞elasticsearchзЪДжРЬ糥忯聁 - 2
11-5 djangoеЃЮзО∞elasticsearchзЪДжРЬ糥еКЯиГљ -1
11-6 djangoеЃЮзО∞elasticsearchзЪДжРЬ糥еКЯиГљ -2
11-7 djangoеЃЮзО∞жРЬ糥зїУжЮЬеИЖй°µ
11-8 жРЬ糥иЃ∞ељХгАБзГ≠йЧ®жРЬ糥еКЯиГљеЃЮзО∞ - 1
11-9 жРЬ糥иЃ∞ељХгАБзГ≠йЧ®жРЬ糥еКЯиГљеЃЮзО∞ - 2
зђђ12зЂ† scrapydйГ®зљ≤scrapyзИђиЩЂ
жЬђзЂ†дЄїи¶БйАЪињЗscrapydеЃМжИРеѓєscrapyзИђиЩЂзЪДзЇњдЄКйГ®зљ≤гАВ
12-1 scrapydйГ®зљ≤scrapyй°єзЫЃ
зђђ13зЂ† иѓЊз®ЛжАїзїУ
йЗНжЦ∞жҐ≥зРЖдЄАйБНз≥їзїЯеЉАеПСзЪДжХідЄ™ињЗз®ЛпЉМ иЃ©еРМе≠¶еѓєз≥їзїЯеТМеЉАеПСињЗз®ЛжЬЙдЄАдЄ™жЫіеК†зЫіиІВзЪДзРЖиІ£
13-1 иѓЊз®ЛжАїзїУ
иѓЊз®ЛжИ™еЫЊпЉЪ

жДЯи∞ҐжЭ•иЗ™@cdsf зЪДжКХз®њпЉБ





2018-08-20 дЄЛеНИ7:39 ж≤ЩеПС
йВ£дєИе•љзЪДиµДжЇРжАОдєИдЄНжФґиієпЉМи∞Ґи∞ҐеИЖдЇЂиАЕ
2018-08-20 дЄЛеНИ10:49 1е±В
@g132g дЄНжФґиієпЉМжШѓеЫ†дЄЇињЩж†ЈпЉМжЙНдЉЪжЬЙжЫіе§ЪдЇЇдЄАиµЈжДЙењЂзЪДзО©иАНпЉБ
2019-05-01 дЄЛеНИ2:58 жЭњеЗ≥
зЃАзЫізИ±дЇЖ иЯєиЯєиµДжЇР дљ†дїђзЃАзЫіжШѓе•љдЇЇ